
Track
What this track is about
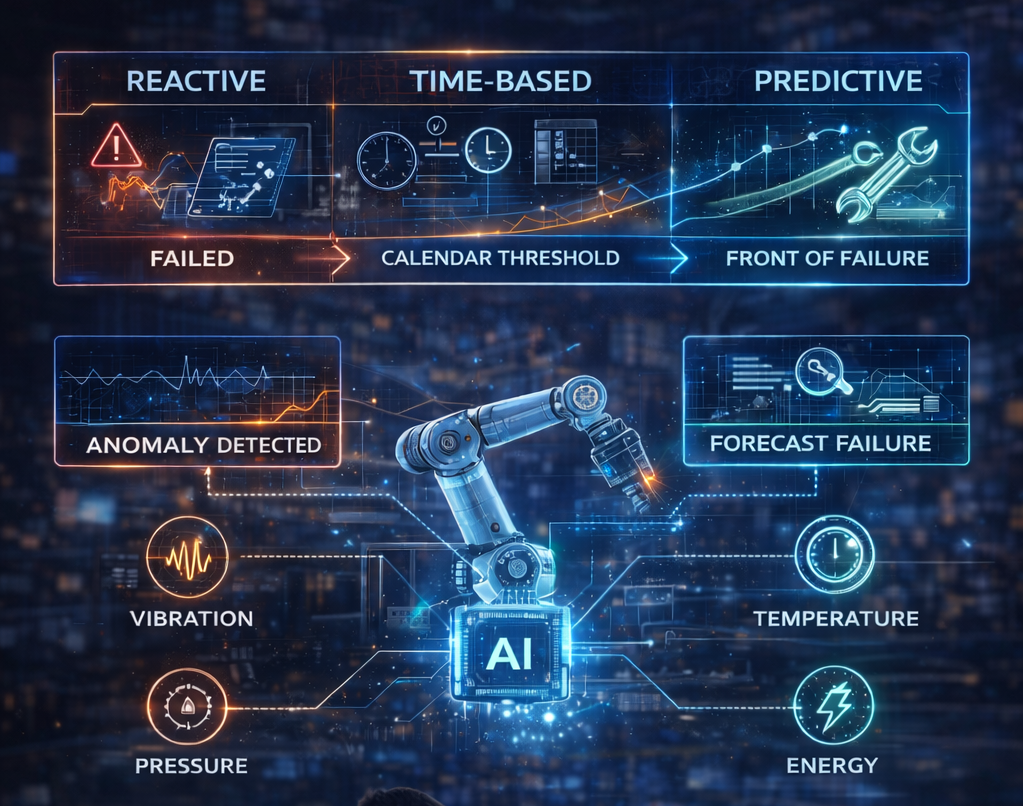
- Moving from reactive and time-based maintenance to condition-based and predictive strategies.
- Using IoT data (vibration, temperature, pressure, energy) plus AI to forecast failures before they hit your OEE.
- Turning your CMMS/EAM into a decision engine instead of a ticket graveyard.

What we work
What we work on inside the track
our services
Typical problems members bring
- We still maintain on OEM schedules, but breakdowns keep surprising us.
- We tried a vision project, but it struggled with lighting changes and product variants.

- Audits are painful; we can’t show end-to-end traceability quickly.
- Our data is scattered; doing proper root cause feels like detective work every time.


What you get
What you get by joining
Practical playbooks
Step-by-step roadmap: “From Excel and breakdowns → to PdM pilot in 90 days.”
Template dashboards: health scores, RUL views, critical asset watchlists.
Peer-tested solutions
Real stories from plants that cut unplanned downtime and maintenance cost using AI-driven PdM.
Expert office hours
Bring your asset list and CMMS screenshots; the community helps you prioritize where AI will move the needle first.
